
Beyond LIKE: Creating Magic-like Semantic Search Experiences
How agile teams can leverage LLMs, Vector Databases, and friends to quickly launch cutting-edge semantic search experiences for fame & profit

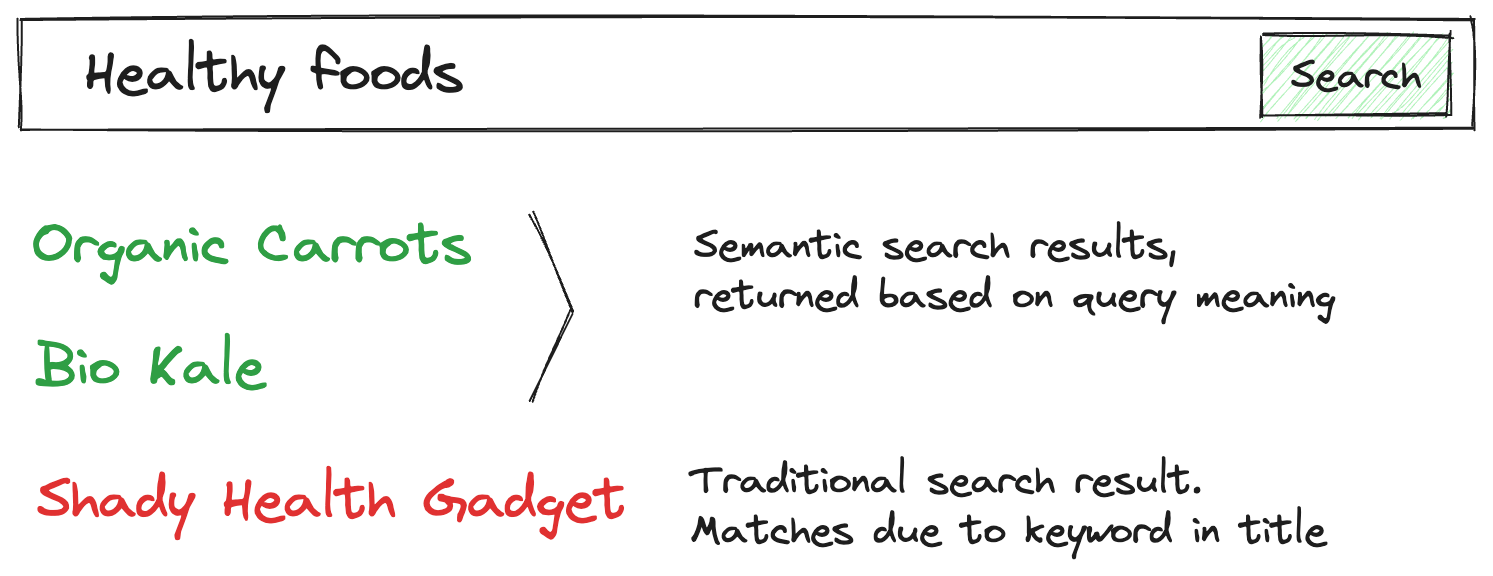
It’s remarkable how so many things are made better with great search. Google made it easy for normal folks to find whatever they needed online, no matter how obscure. IDEA’s fuzzy matching and symbol search helped programmers forget the directory structure of their code bases. AirTag added advanced spatial location to my cat. A well-crafted discovery feature can help add that “wow” factor that iconic, habit forming products have.
In this post I’ll cover how a fast-moving team can leverage Large Language Models (LLMs), Vector Databases, Machine Learning, and other goodies to create a wow-inspiring search and discovery experience with startup money and (lack of) time.
Semantic Search
Semantic Search is a search method for surfacing highly relevant results based on the meaning of the query, context, and content. It goes beyond simple keyword indexing or filtering. It allows users to find things more naturally and with better support nuance than highly sophisticated but rigid traditional relevancy methods. In practice, it feels like the difference between asking a real person or talking to a machine.
Tech companies from all over the world are racing to add these capabilities to their existing products. Instacart published an extensive article on how they added semantic deduplication to their search experience. Examples of companies implementing some form of semantic search include eBay, Shopee, Ikea, Walmart, and many others.

The reason for this rush towards semantic search is simple: more relevant results = happier customers = more money. Discovery, relevancy, and trustworthiness are some of the hardest problems to solve in e-commerce, and an entire ecosystem exists to help companies solve them.
Many companies working on semantic search today solve this problem using document embeddings - a way of representing meaning as vectors. Since semantic search alone may not be able to provide enough relevant hits, traditional full text indexing is used as a backup method. A feedback loop is added to track user interactions and use them to provide super relevant results through result re-ranking.
This method has three key processes: indexing, querying, and tracking.

Indexing is done by converting a document’s content to an embeddings vector through a text-to-vector encoder (ex: OpenAI’s Embeddings API) and inserting it into a Vector Database (ex; Qdrant, Milvus, Pinecone, etc.). Documents are also indexed in a traditional full text search engine (ex: Elasticsearch).
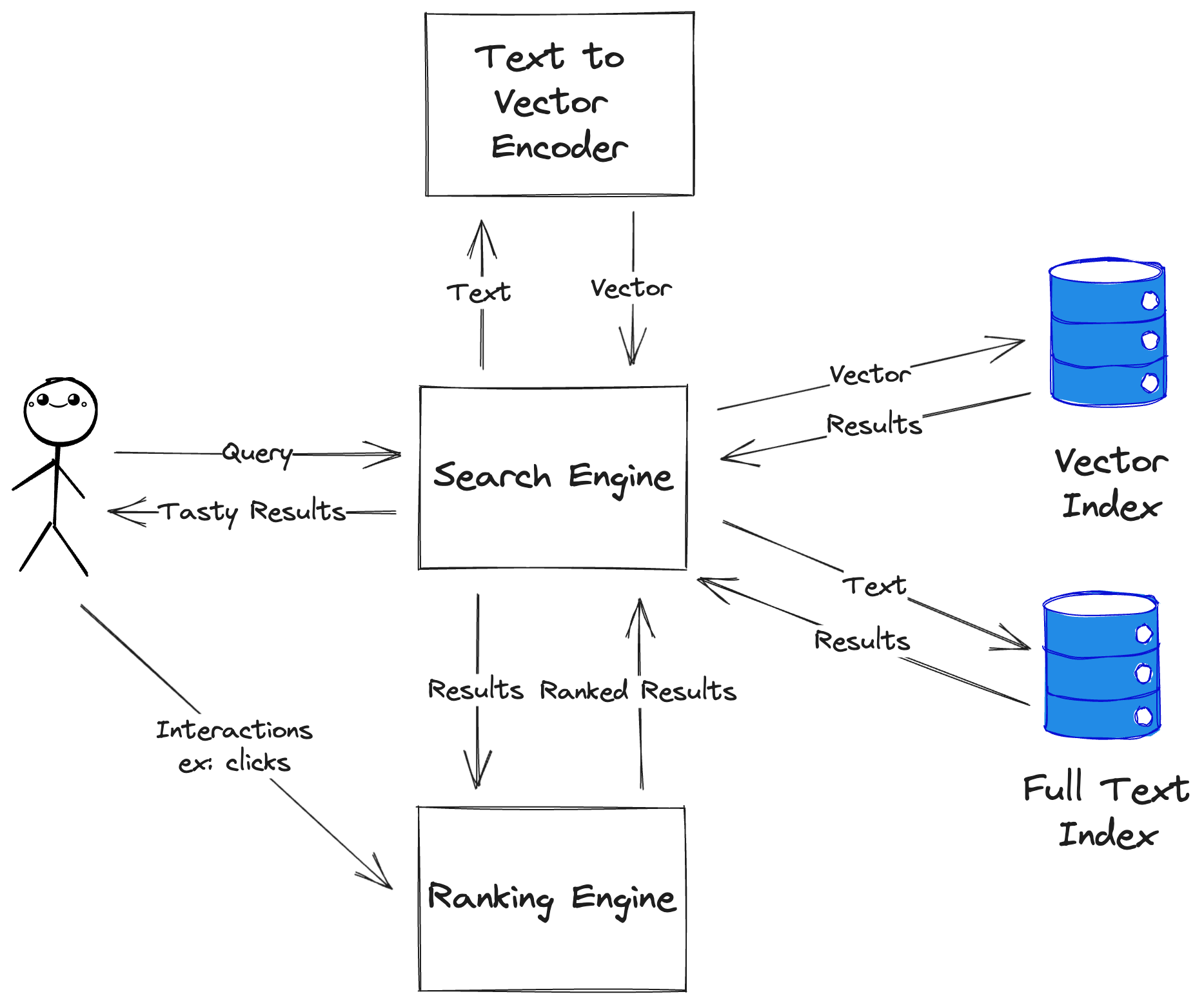
Querying relies on encoding incoming queries into vectors (preferably using the same encoder as the previous step) and querying the vector database using them. These results are then combined with traditional full text results and re-ranked for relevancy. This combination is usually referred to as “hybrid search”. Search re-ranking is usually a complex problem, and often relies on a mix of machine learning and heuristics.
Tracking involves capturing important user interactions - ex: clicking on results, liking items, etc. - and using these events to update the machine learning models involved in re-ranking. This provides a feedback loop that uses user input to continuously improve relevancy.
MVP
Most companies should not copy the architectures of large tech behemoths, startups least of all. The realities are just too different. That’s not to say that we can’t borrow a few tricks from them to implement a reasonably good solution with non-infinite budget and time.
The approach I’m going to explore here is based on mixing semantic search and full text results, re-ranking them for increased relevancy, and tracking user feedback to improve search quality. This is a combination of hybrid search (full text + semantic) and learn-to-rank (closed loop re-ranking).
Vector similarity search will be addressed by Qdrant. Qdrant is as fast vector database with a wonderful developer experience. Getting started with it was a breeze, the company recently raised a healthy investment round, and the team is actively responding to community feedback and improving the product. A great system to start your vector journey with, especially considering some of the alternatives.
I am also using OpenAI’s Embeddings API to encode text into embeddings. OpenAI’s text-embedding-ada-002 model is quite good, but there are other players in the market today. You can also checkout Cohere or even self-hosted models, like all-MiniLM-L6-v2. I recommend starting with cloud-hosted ones for simplicity though.
Our full text search part will be done by ElasticSearch (ES). ES is a mature, batteries-included search system with many capabilities. Interestingly, Elastic seems to be deeply interested in vector search. Definitely something to keep an eye on.
Re-ranking will be handled by Metarank. Search re-ranking is a hard problem, and I’m surprised that there is a relatively easy to use open source solution available. The re-ranking part is somewhat complex (especially when you get to fine-tuning), so I would recommend that you first get the basic indexing and search working and add re-ranking on top.
NOTE: the reason why we usually need to combine semantic search and full text results is that semantic search may not return enough hits. Your specific results may vary, so feel free to experiment!
Indexing
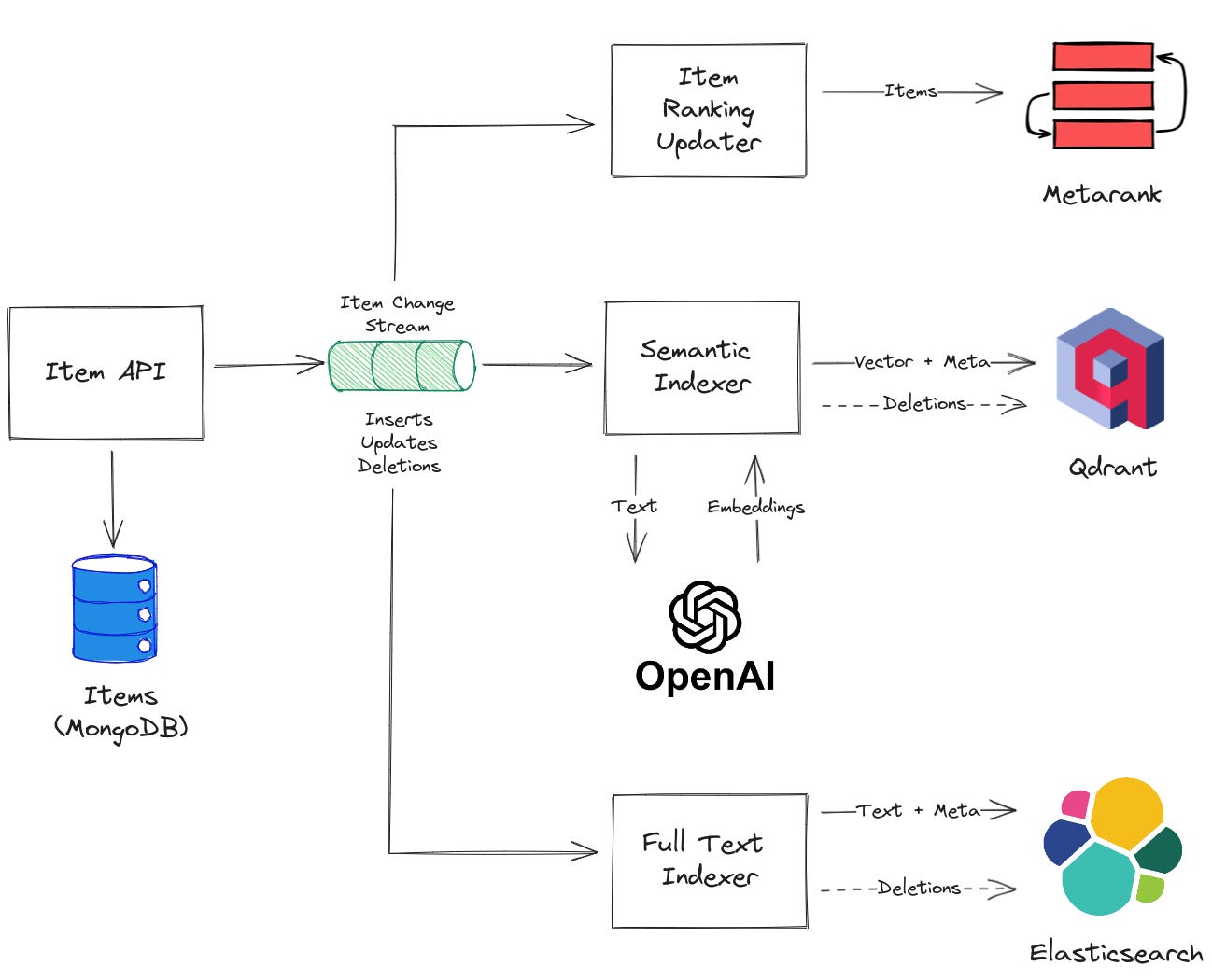
The first step is to index items for search. Items could be anything - products, locations, sellers, images, etc. Items are stored in the main database (MongoDB in this example), which serves as the source of truth.
To index items we will push changes (inserts, updates, and deletions) into a Kafka topic, which will then be consumed by multiple processors. Redis queues would work too. This is a pull-type architecture and it is quite robust in production. You could call each system directly from the Items API, but this can easily lead to partially indexed items.
Three processors consume this topic:
Full Text Indexer: updates the full text index (ElasticSearch in our example).
Semantic Indexer: assembles text strings from item changes (ex: product titles + description), encodes them into vector embeddings, and saves them to the vector database (Qdrant).
Item Ranking Updater: updates Metarank’s item metadata.
Note that none of these systems will generally contain the full item data, which is usually unnecessary (and costly).
Querying
This is where things get interesting.

Our Search API works in four major processes:
Search: the first step consists in sending the query to our two providers - Full Text (ElasticSearch) and Semantic (Qdrant).
Notice that the semantic search provider needs to first convert the query into vector embeddings much like the semantic indexer.
This is a good step to perform some pre-filtering, like simple criteria (ex: category IDs), geographical radius, etc.
Re-ranking: once the search service collects all hits it routes the full set to the Result Re-ranker, which re-orders them for relevancy using Metarank.
Metarank does not work without some initial data. You can solve this cold start problem by having a simple ranker as a fallback. I had good results with just adding the top 3 semantic hits at the top and the full text ones after. This generally doesn’t look half bad, and it’s just for a little while as real users start using the system. For a more sophisticated approach, check out this amazing article by Metarank’s own co-founder.
Result Generation: search hits do not generally contain all item information. In order to return a complete human-readable result set we will “hydrate” our ranked hit list into a ranked item list.
This is a good place to cache the result list with a relatively short TTL. This helps a lot with things like pagination and sorting.
You may also want to store search session metadata here. This is usually not the same as a user session. This allows you to group search and result queries later for analysis and ML, and is a parameter that we can pass to Metarank to improve ranking relevancy.
Result Tracking: once we have a fully hydrated and paginated set of results we will update Metarank with the exact list of items we are showing users.
This could also be accomplished from the frontend if we want to keep this API simple and fast.
NOTE: I mapped the different components for the sake of clarity. If you are operating in a small team or startup I would not recommend going around creating tons of micro services!
Tracking
We need to track how users interact with our results so that we can create a learn-to-rank feedback loop. Examples of tracked interactions include viewing results, clicking them, liking them, etc. The least interaction you should track are result clicks.
This is accomplished by sending these events to a lightweight tracking API, which quickly pushes them to a Kafka topic (a Redis queue or similar would work as well). Since not all data is available in the front end, we may want to first enrich them with internal metadata. Finally, this enriched result is shipped to Metarank (directly reading from Kafka or through its HTTP API) and to a data lake for future analysis.

I am also keeping this at a high level since building such data pipelines by hand nowadays is usually not recommended, especially to small teams. There are plenty of great tools available (ex: Segment, Rudderstack, Fivetran, dbt, Snowplow, etc.) that can help you build a strong data pipeline or plug Metarank into an existing one. For example, here is a chart showing Metarank’s native integration with Snowplow:
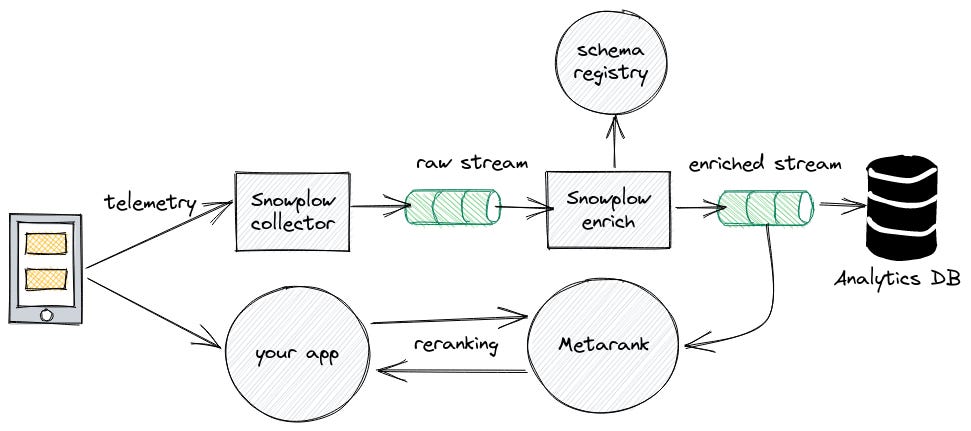
NOTE: This is an optional step, and adds quite a bit of complexity to the system. I suggest you implement this only if you are committed to implementing a full blown learn-to-rank system.
What’s Next
Creating great search experiences has never been easier. Semantic hybrid search is a solid first step into providing search results beyond LIKE. Customers are slowly but surely becoming used to this increased level of relevancy, which raises the bar for everyone.
Luckily for small teams, the tooling ecosystem is developing fast.
Many search tools are striving for convergence. Elasticsearch has a working (but slow) vector search function. Qdrant added lots of filtering capabilities (like match and geo-radius). Metarank ships with a semantic similarity recommendation model. There may soon come a time where we have a simple, batteries-included system that can do a good job across the board from the get go.
You can also forgo much of this work and use Algolia NeuralSearch if you have a small number of items, a moderate traffic app (ex: B2B SaaS dashboard), just want to ship a POC fast and see how users respond, or infinite money. It’s a powerful, fully hosted solution from a company that knows search deeply.

There are many ways to get started, and few excuses to keep giving your users a meh search experience!
Plz help me